
I’m excited to announce that Spark 1.2 is finally out!
Spark is the go-to solution for real-time GPU texture compression, offering high-performance codecs that deliver high-quality results at real-time speeds. It enables developers to efficiently compress textures directly on the GPU, reducing memory usage and improving rendering performance across a wide range of platforms.
With Spark 1.2, I’ve taken things even further with major optimizations, new compression formats, and expanded platform support:
- Major optimizations:
f16vectorization of all codecs and improved performance on all devices, but especially Bifrost GPUs, and a much faster EAC codec. - New formats: including an improved BC3-YCoCg codec, HDR (RGBM) support, a real-time ETC2 codec that matches the quality of offline codecs, support for larger block sizes starting with ASTC 6×6, and a new type of codec optimized for transcoding applications.
- New platform support: Extended compatibility to Android TV and consoles.
For these release notes, I’m trying a slightly different format. Instead of just sharing the highlights on social media, I’m using my blog to provide a more personal and in depth update. I’m afraid I will have to keep some of the specifics under wraps, so I won’t be sharing as much implementation details as in my typical blog posts, but I hope I can offer enough insight to satisfy my regular audience. If you are interested, read on!
The initial focus for this release was improving vectorization to enhance performance on RDNA, consoles, and Mali GPUs. But along the way, I ended up adding far more than planned. Looking through my notes, I’m surprised by just how much made it into this release.
Most of these features weren’t even on my roadmap. Some came from licensee requests, which is great, as I want my clients to feel they’re getting real value for their financial support. Others were simply ideas that had been lingering in the back of my mind until something clicked, and I couldn’t resist tackling them. And then there were features added in response to prospective clients’ needs. While many of these additions are valuable, this reactive approach hasn’t necessarily translated into closing deals.
This has made me rethink my priorities. Moving forward, I plan to stay more focused on long-term goals rather than chasing feature requests from potential clients who haven’t committed to a license yet. That said, I think all my existing clients can attest that once they come on board, I go all-in to support them. If there’s a missing feature they need, I’ll bend over backward to make it happen.
With that out of the way, let’s dive in:
Optimizations
For this release, I’ve revisited nearly all the codecs, profiling them across multiple devices and applying numerous optimizations. Below is a brief overview of just the most significant improvements:
f16 vectorization
Many devices can issue two f16 instructions in parallel, as long as the operands and the result are packed into the same register. This often doubles the throughput compared to f32 operations. While compilers attempt to leverage this capability, they are limited by the strict floating-point evaluation order requirements and the way data is laid out in registers. If values are not stored in the same registers, the overhead of shuffling them can outweigh the benefits of dual-issue execution. However, by structuring the code to make the compiler’s job easier, we can maximize these optimizations. I refer to this as f16 vectorization since the techniques used are closely related to traditional SIMD vectorization strategies.
In Spark 1.1 only some of codecs were vectorized. My initial approach to vectorization wasn’t always producing optimal results and it was tedious; I couldn’t easily share code between the vectorized and non-vectorized versions. While the resulting code performed better on devices with packed f16 math support, it was slower on other devices.
With the new approach, the vectorized version now performs as well or better than the scalar version in nearly all cases. This simplifies shader selection and distribution, making it possible to use the f16x2 variant of the codecs almost everywhere.
Massive Bifrost improvements
One class of devices that benefited greatly from these optimizations are Bifrost devices. These devices support dual-issue, but my initial experiments resulted in reduced performance. It turns out the problem was that the Bifrost compiler was not unrolling loops aggressively enough.
The vectorized code relies on loop unrolling and constant folding to eliminate table lookups, which are necessary to reorder the access to block texels. Forcing the frontend to unroll the loops had a massive performance impact and improved the effectiveness of the the vectorizing optimizations.
The following chart shows the speedups I was able to achieve with respect to Spark 1.1:
Moreover, explicit loop unrolling also led to performance gains on many Adreno devices, though the improvements were not as pronounced as on Bifrost GPUs.
Improved EAC codec
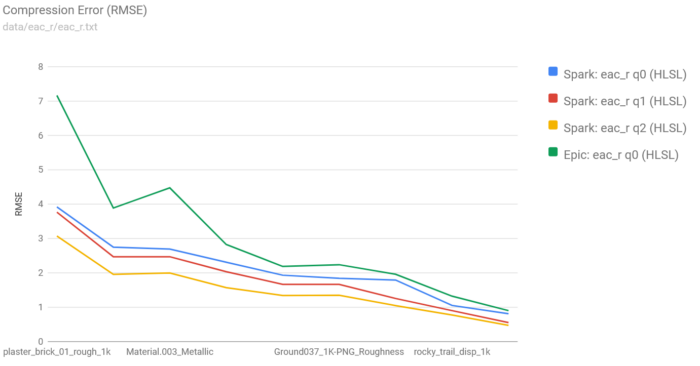
One of the codecs that has seen the greatest improvements is the EAC Q0 codec, thanks to the elimination of table lookups. This has improved performance across all devices, but the speedups are most notable on Bifrost devices due to the improved f16 vectorization:
The only other real-time EAC codec I’m aware of is the one included with Unreal Engine. However, Epic’s codec delivers significantly lower quality:
And with these optimizations it runs much slower in comparison:
New Codecs
BC3-YCoCg
As one of the inventors of the scaled BC3-YCoCg format, I’m disappointed that there have been no more innovations in this direction. Most implementations still use almost the exact same code we published 18 years ago. While it’s possible to write better encoders that target the same format, there’s also an opportunity to modify the color transform to achieve additional gains.
Our original approach was constrained by the need to run on the CPU using integer SIMD instructions. To achieve this efficiently, it scaled the CoCg components using one of three predefined factors, which was then stored in the blue channel. In the shader, the chrominance was reconstructed by extracting the scale stored in the blue component and dividing the red and green components.
Today, we can remove this constraint by allowing an arbitrary scaling factor, storing its reciprocal, and eliminating the division in the decoder. With a slightly more sophisticated encoder, we can significantly reduce the error while also simplifying the decoder, which runs far more frequently. However, special care must be taken to ensure that the scale is reconstructed precisely so that the CoCg values are divided by the exact same factor used during encoding.
Below is the proposed decoding procedure. Notice that the scale no longer requires any transformation:
f32x3 spark_ycocg_to_rgb(f32x4 ycocg) {
f32 Co = ycocg.r;
f32 Cg = ycocg.g;
f32 scale = ycocg.b;
f32 Y = ycocg.a;
#if SPK_BC3_YCOCG_WAVEREN
scale = 1.0 / ((scale * (255.0 / 8.0)) + 1.0);
#endif
Co = (Co - cocg_offset) * scale;
Cg = (Cg - cocg_offset) * scale;
return saturate(f32x3(Y + Co - Cg, Y + Cg, Y - Co - Cg));
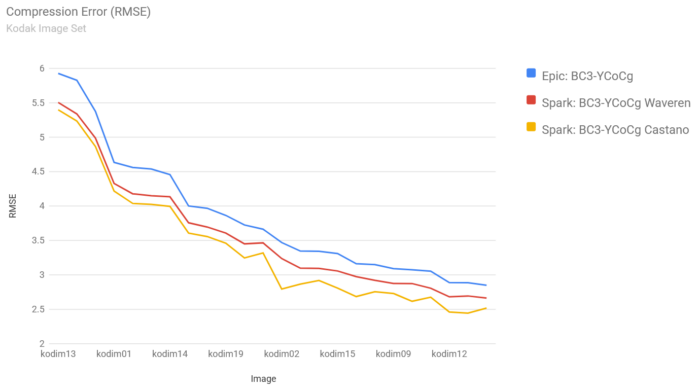
}The chart below compares our original BC3-YCoCg codec (as used in the Unreal Engine) with Spark’s encoder using the same BC3-YCoCg format, as well as our improved scheme that uses a continuous scaling factor. The error is significantly lower when using the proposed approach:
An important caveat is that the scaled YCoCg color transform is not linear, which can lead to bilinear interpolation artifacts at block boundaries when adjacent blocks use different scale factors. This issue is most noticeable in images with drastic chrominance variations, such as the one shown below:

However, these artifacts can be easily avoided by constraining the scaling factors and ensuring they are never too close to zero.

HDR Codecs
A common application of real-time texture compression is to compress light probes that are generated at runtime. Light probes usually store high dynamic range (HDR) colors. Today we have GPU texture formats that can represent HDR colors efficiently, but on mobile ASTC HDR is not available on all devices. In particular, iOS devices prior to A13 (iPhone 11) lacked ASTC HDR support, and even today ASTC HDR is missing from all PVR devices and many Qualcomm ones.
For our first HDR codecs I’ve focused on a solution that works everywhere by using the RGBM color transform. This allows extending the typical LDR range by about 16x while still providing good quality. I first used this format to encode the lightmaps of The Witness. Back then I used least squares optimization of the M component to minimize the RGB error, but I’ve found a similar approach for error compensation that works even better and is suitable for real-time encoding.
One of the challenges is constraining the M values to avoid bilinear interpolation artifacts. Our approach does not eliminate these completely, but the M values are chosen such that they don’t change abruptly, and therefore artifacts are hardly noticeable.
The following example compares a naïve RGBM encoder:

Against the new error compensation:

Notice the overall smoother results and lack of quantization errors near the transitions between bright and shadowed areas.
Getting this to work on the actual mobile devices was tricky! I thought the ASTC format was specified exactly and that all vendors conformed to it, but it turned out that was not the case. In particular, when using the EXT_astc_decode_mode extension to select the 8-bit decode mode the way rounding is done is device-dependent.
Typically these differences only result in off-by one errors and are hardly noticeable. However, in our case the RGB components are divided by M in the encoder and they reconstructed by the decoder multiplying by M. If the M value in the decoder differs slightly from the M value expected by the encoder, then significant errors can occur and this does in practice result in significant artifacts.
Here’s the diff output of the same RGBM-encoded texture on three different devices:
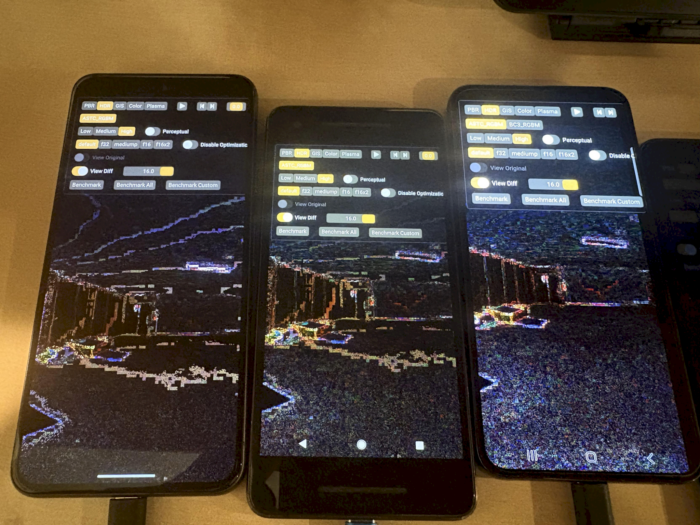
Fortunately, the solution to this problem appears to be quite simple. Since our textures are encoded in real-time we can adapt the encoding scheme to the underlying hardware. This is something that would not be possible if these textures were encoded offline!
The BC3 format has similar issues, every vendor implements it in a slightly different way, but the BC3-RGBM encoder is designed so that these small implementation differences do not make a significant difference.
It is possible to achieve higher quality and greater range by targeting native HDR formats. Krzysztof Narkowicz has a free BC6H encoder that he described in this GDC 2016 presentation. Krzysztof’s encoder has two modes, one that targets a single partition and another that uses a more exhaustive partition search. The former has similar performance characteristics to our RGBM codecs and can be compared directly. While RGBM has a more constrained range and higher quantization artifacts, the BC6H codec often suffers from block-compression artifacts that are not present in ours:

QUALITY == 0)
In future updates I plan to provide improved real-time BC6H and ASTC-HDR codecs that don’t suffer from these issues.
ETC2
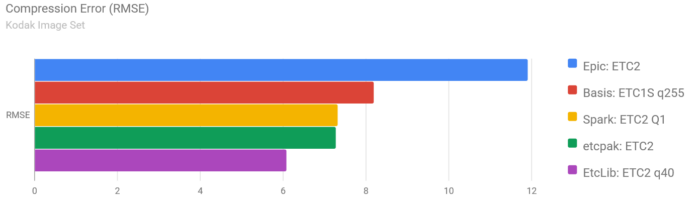
Spark 1.2 also introduces a new ETC2 codec. Initially I didn’t have high expectations about the possibilities of this format, but I’m actually very pleased with the results. The quality of this codec matches or surpasses offline encoders like Basis and etcpak, yet it runs in real-time!
This was achieved through a combination of table selection heuristics, accurate quantization, and a novel least squares optimization technique.
- At the lowest quality level, the ETC codec targets the ETC1s subset.
- At medium quality, mode selection is based on a heuristic, and it targets both ETC1 partitions and endpoint encoding modes, as well as the ETC2 planar mode.
- At high quality it simply targets planar mode more aggressively and instead of using a heuristic, it actually evaluates the planar mode error and selects it when it’s below a certain threshold.
The planar mode coefficients are determined using least squares optimization. This is particularly tricky to do with reduced precision, but I was able to express all the computations in f16. The exception however is the evaluation of the residual, so in high quality mode I rely on direct error evaluation instead. It’s possible to vectorize this code aggressively, so the end result is faster than evaluating the residual in full precision.
Unfortunately PowerVR devices have trouble with planar mode optimization and are currently limited to the low quality level. I’ll be talking to ImgTec to try to address this and if there’s enough interest I’ll try to address it in the future.
With the addition of this codec, Spark can serve as a drop in replacement for all the codecs in the Unreal Engine. This can make a huge difference in mobile applications using virtual texturing or Lumen, both of which rely on real-time texture compression.
Spark‘s quality is not only much higher:
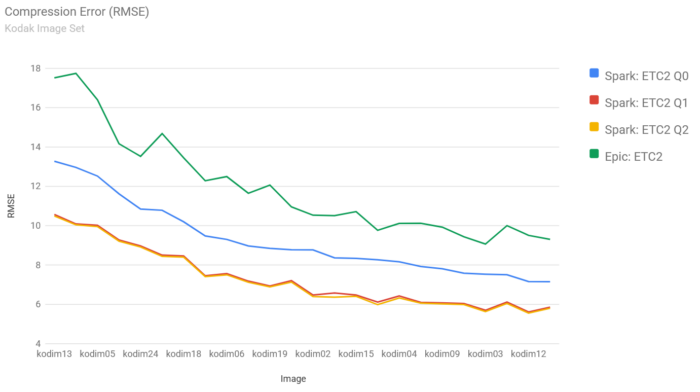
But it achieves that with much higher performance. The table below shows the throughput in MPix/sec:

The results speak for themselves, Spark is on the left and Epic’s encoder on the right:

ASTC 6×6 & Streaming Codecs
Supporting additional block sizes has been a goal from day one, but larger block sizes are particularly challenging due to the large number of registers required to hold all the texels in a larger block. It’s not uncommon to have compute kernels take a large number of texture samples, for example, to perform a convolution. The challenge with block compression is that the shader needs to process these samples multiple times, making register pressure a limiting factor.
The key breakthrough in Spark 1.2 is an encoding algorithm that only iterates over the texels once. This enables a new class of streaming codecs, which process input colors sequentially. Once a color is processed, it’s never used again, allowing its register to be recycled.
Additionally, I developed a least squares optimization method that requires only one-third of the registers used in traditional implementations. Together these two innovations enable codecs that can handle arbitrary block dimensions and are suitable for real-time use on all devices.
Despite these advancements, compilers still struggle to generate optimal code. They often front-load too many texture samples or introduce unnecessary register spills in cases that could be avoided. While the results are already practical, I plan to continue refining these kernels and collaborating with IHVs to fully unlock their potential.
Currently, Spark 1.2 supports only the 6×6 block size, but this approach can be extended to other dimensions. However, due to the inherent constraints, these codecs cannot explore as much of the search space as 4×4 codecs, meaning quality will always be somewhat lower. That said, the results are still suitable for many applications.
The following example shows the quality difference between ASTC 6×6 (left) and 4×4 (right) on a couple of textures:

Sideband Data Codecs
One of the innovations that I’m most excited about is the use pre-computation of sideband data to assist the encoders.
A common application of real-time texture compression is to transcode textures from formats that are more suitable for transmission and storage. For example, some applications use JPEG textures downloaded from the web, others use formats like AV1 for improved quality and compression ratios and to leverage the hardware decoders on mobile devices, and finally many developers are exploring the possibilities offered by new neural texture encoding schemes. All these applications benefit from transcoding these textures to GPU formats. It reduces their memory footprint and power consumption, and it improves runtime performance.
In all these cases the compressed data is known in advance. To transcode these representations to GPU texture formats we can use a standard real-time encoder, but since we know the input data we can do better. It’s possible to precompute a small amount of per-block sideband data to assist the encoder to improve the quality and its performance.
This release features 3 codecs with sideband data.
- An ASTC 6×6 codec that uses 8 bits per block (2/9 bpp)
- An ASTC 4×4 codec that uses 2 bits per block (1/8 bpp)
- A BC7 codec that uses 2 bits per block (1/8 bpp)
The ASTC 6×6 sideband codec produces higher quality results than the standard ASTC 6×6 codec. It lifts some of the limitations of the streaming codec allowing it achieve higher quality and to do so with better performance.
The ASTC 4×4 sideband data codec (in yellow) is my highest quality ASTC codec. It produces much higher quality results than the standard Q2 ASTC codec (in blue) and slightly better than the Q3 codec (in red), which is not yet available in the GPU.
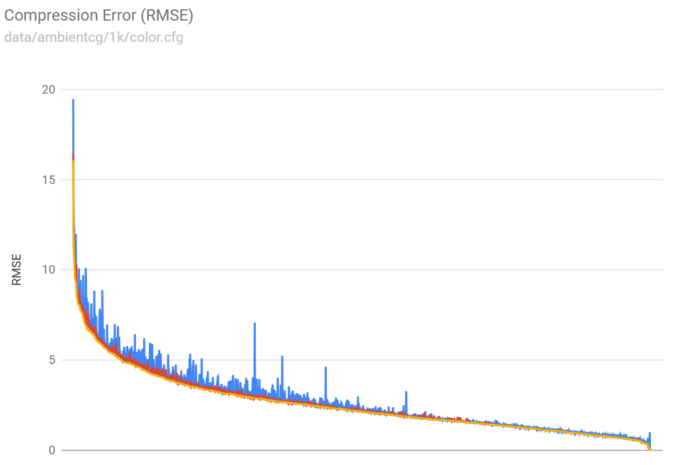
The BC7 sideband codec has similar characteristics.
I feel like I’m only scratching the surface of what’s possible with strategies like these. The size of the sideband data is fairly small already, but it can usually be compressed very effectively and it’s possible to use Lagrange optimization to balance quality against storage and performance by choosing block modes that compress better or reduce divergence.
New Devices
Android TV
Spark 1.2 introduces support for Android TV, expanding compatibility to a broader range of devices, including ultra low-end GPUs like the Mali-G31 and PowerVR GE9215. These devices are heavily ALU-limited, making our optimization work especially impactful.
To showcase these improvements, I updated the Android demo to support “leanback” setups and Android TV input methods. I’m particularly pleased with how well ImGui works in scenarios like this.

Consoles
I finally got access to the Xbox and PlayStation SDKs. While the codecs didn’t work out of the box, I was able to get the expected results with some minor adjustments. There’s a lot of room for optimization and opportunities to leverage the lower-level access these platforms provide. However, interest in console support seems to have stalled for now, so further work is on hold until customers specifically request it.
Final Words
You can evaluate all these new codecs using the Spark View web app and test their performance on your device with the Android demo app.
If you’ve made it this far and still want to learn more, I’ll be at GDC in a couple of weeks and would be happy to meet and chat about anything related to texture compression.
For licensing inquiries or anything else, feel free to reach out at spark@ludicon.com.